If you’re using Headless WordPress and aiming to build a documentation site alongside a blog, you might consider integrating MDX or Markdown files. These formats make it simple for developers to create and edit content, which is especially handy if you want to open up your docs to contributions from the open-source community.
While WordPress offers powerful tools for indexing and retrieving blog content, challenges arise when you want to add search functionality that also includes MDX or Markdown-based documentation files. Without a unified search solution, users could be left searching in silos—missing out on relevant information across your content types.
In this guide, we’ll walk you through using the WP Engine Smart Search plugin to create a seamless search experience that indexes both your WordPress content and MDX/Markdown files. With this setup, you’ll be able to serve a Next.js application where users can search blog posts, documentation, and any additional content in a unified experience.
Table of Contents
- Prerequisites
- WP Engine Smart Search
- Steps
- Install and Activate Smart Search
- Configure Smart Search
- Smart Search Environment Variables
- Configure Next.js and App Router
- Installing Dependencies
- Environment Variables
- Next Config File
- Create MDX Files And Paths
- Global MDX Components
- Smart Search Plugin
- Components Directory
- Search Bar Component
- Layout, Heading, and NavBar
- The route.js File
- Test The Search Functionality
- Conclusion
Prerequisites
Before reading this article, you should have the following prerequisites checked off:
- Basic knowledge of Next.js 15 App Router
- Next.js boilerplate project that uses the App Router
- A WordPress install on WP Engine with Smart Search activated
- A basic knowledge of WPGraphQL and headless WordPress
- A basic knowledge of MDX and Markdown
In order to follow along step by step, you need the following:
- A Next.js project that is connected with your WordPress backend with a basic home page and layout.
- A dynamic route that grabs a single post by its URI to display a single post detail page in your Next.js frontend
If you do not have that yet and do want to follow along step by step, you can clone down my demo here:
https://github.com/Fran-A-Dev/smart-search-with-app-router
If you need a WordPress install, you can use a free sandbox account on WP Engine’s Headless Platform:
WP Engine Smart Search
WP Engine Smart Search is an Add-on for WP Engine customers that improves search for headless and traditional WordPress applications. It is designed to improve search result relevancy, support advanced search query operators, and add support for advanced WordPress data types.
We will use its public API for this article.
Smart Search search is included in paid plans with WP Engine accounts.
Steps
Install and activate Smart Search
Steps to install and activate the Smart Search plugin:
- Go to your WP Engine User Portal and follow the steps to enable it here.
- Navigate to your WP Admin
You should have this:

Now that you have Smart Search activated in your WordPress backend, navigate to WP Engine Smart Search > Index data and you should see this page:

A content sync sends all pre-existing content on the WordPress site to WP Engine Smart Search for indexing. This ensures the plugin knows exactly what content exists so it can serve the best results to site users. Click on the “Index Now” button and this will Index your content.
Configure Smart Search
Now that we have Smart Search installed, let’s go ahead and configure it. For this article, we will use the default settings. In the WP admin sidebar, click on WP Engine Smart Search > Configuration. You will see this page:

Smart Search will default to “Full text” and “Stemming” for the search config. We will stick to these for this guide, but feel free to try the other options on your own.
Smart Search Environment Variables
Everything is installed and configured. We need to grab the environment variables we are going to use to communicate with Smart Search on our frontend. Navigate to Settings in the Smart Search menu option and it will take you to this page:
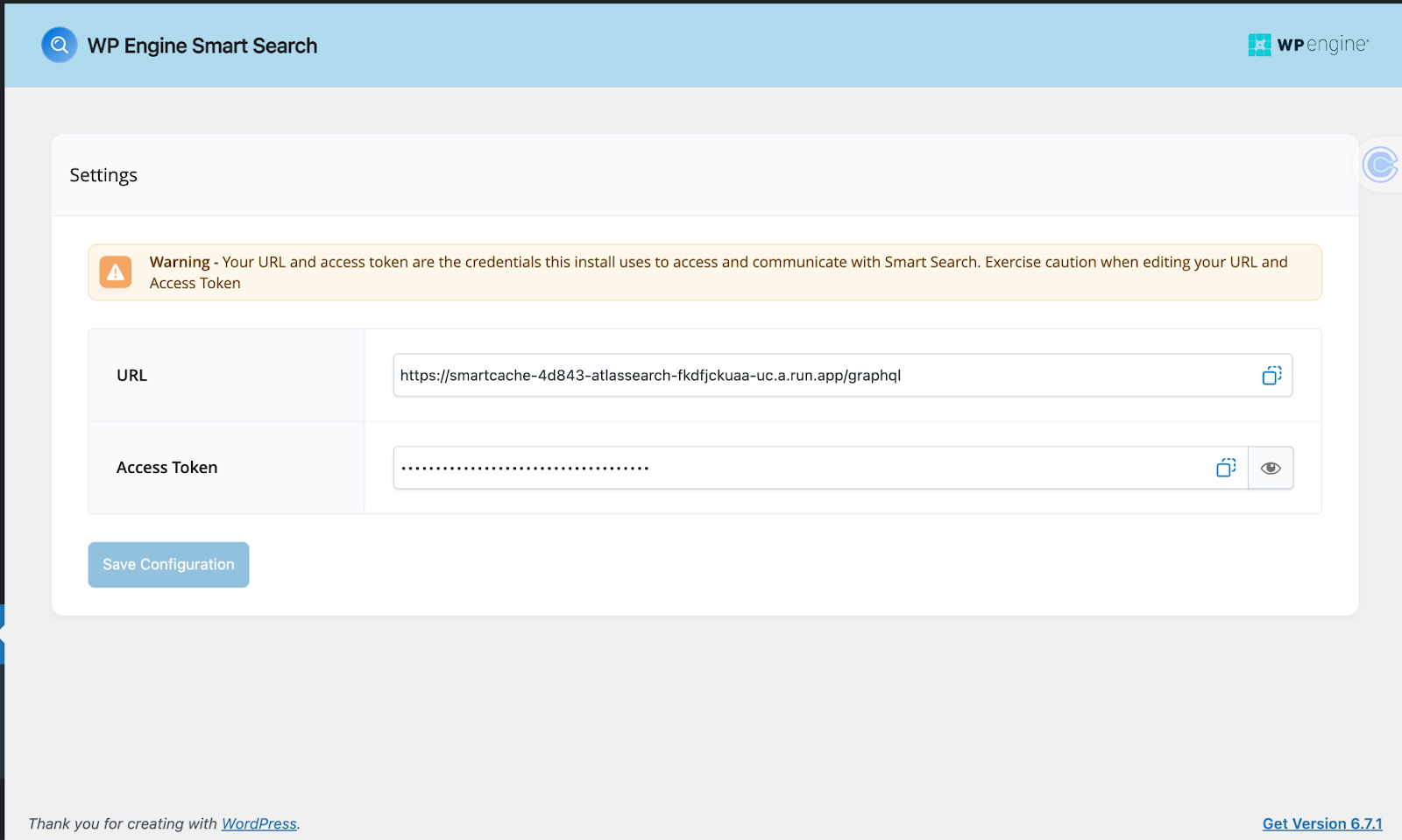
The Access Token and URL in WP Engine’s Smart Search plugin are essential credentials that enable communication between your WordPress site and the Smart Search service.
The URL points to the Smart Search API endpoint, which ships with a GraphQL interface. This interface allows you to query and manage indexed data with GraphQL.
The Access Token is used for secure authentication to ensure that only authorized requests interact with the search backend.
Save these two variables since we will need them in the next section.
Configure Next.js and App Router
If you followed along in the prerequisites section of this article, you should already have a Next.js frontend spun up with a dynamic route that displays a single post detail page from WordPress via its URI.
Installing Dependencies
The first thing we will need to do is import the necessary package dependencies. In your terminal, run the following command:
npm i downshift lodash.debounce json5 @next/mdx shikiji-transformers next-secure-headers rehype-mdx-import-media rehype-pretty-code rehype-slug http-status-codes
Code language: CSS (css)The packages we installed do the following:
Packages:
downshift: Provides functionality for building autocomplete or dropdown experiences.lodash.debounce: A utility for debouncing functions.@next/mdx: Allows you to use .mdx files in a Next.js project.shikiji-transformers: A collection of common transformers for shikiji, which we will use for adding syntax highlighting to the code blocks on our documentation pages.next-secure-headers: Helps secure Next.js apps by adding headers.rehype-pretty-code: Formats and highlights code blocks in markdown or MDX.rehype-slug: Adds IDs to headings in markdown or MDX for easier linking.http-status-codes: Constants enumerating the HTTP status codes. Based on the Java Apache HttpStatus API
These packages will allow us to have our MDX files with nice, clean syntax highlighting and code blocks. It will also optimize our search UI experience.
Environment Variables
The following step is to create a .env.local folder at the root of the project so that we can add the environment variables necessary to our project.
Once that is created, add these keys and values to it:
NEXT_PUBLIC_GRAPHQL_ENDPOINT=https://your-wordpress-site.conm g
/graphql
NEXT_PUBLIC_WORDPRESS_HOSTNAME=https://your-wordpress-site.com
NEXT_PUBLIC_SEARCH_ENDPOINT=https://your-smartsearch-endpoint.uc.a.run.app/graphql
NEXT_SEARCH_ACCESS_TOKEN=your-access-token
Code language: PHP (php)The access token and endpoints will allow our app to access our smart search and WordPress API’s.
The next.config.mjs file
We have our packages dependencies installed. Now, let’s setup our Next.js project to support MDX and Webpack for our search plugin.
In the root of the project, you will find the next.config.mjs file and it should look like this:
// next.config.mjs
import { env } from "node:process";
import createMDX from "@next/mdx";
import { transformerNotationDiff } from "@shikijs/transformers";
import { createSecureHeaders } from "next-secure-headers";
import rehypeMdxImportMedia from "rehype-mdx-import-media";
import { rehypePrettyCode } from "rehype-pretty-code";
import rehypeSlug from "rehype-slug";
import smartSearchPlugin from "./lib/smart-search-plugin.mjs";
/**
* @type {import('next').NextConfig}
*/
const nextConfig = {
trailingSlash: true,
reactStrictMode: true,
pageExtensions: ["js", "jsx", "mdx", "ts", "tsx"],
sassOptions: {
includePaths: ["node_modules"],
},
eslint: {
ignoreDuringBuilds: true,
},
redirects() {
return [
{
source: "/discord",
destination: "https://discord.gg/headless-wordpress-836253505944813629",
permanent: false,
},
];
},
images: {
remotePatterns: [
{
protocol: "https",
hostname: process.env.NEXT_PUBLIC_WORDPRESS_HOSTNAME, // Updated hostname
pathname: "/**",
},
],
},
i18n: {
locales: ["en"],
defaultLocale: "en",
},
webpack: (config, { isServer }) => {
if (isServer) {
config.plugins.push(
smartSearchPlugin({
endpoint: env.NEXT_PUBLIC_SEARCH_ENDPOINT,
accessToken: env.NEXT_SEARCH_ACCESS_TOKEN,
})
);
}
return config;
},
};
const withMDX = createMDX({
options: {
// Add any remark plugins if needed
rehypePlugins: [
rehypeSlug,
[
rehypePrettyCode,
{
transformers: [transformerNotationDiff()],
theme: "github-dark-dimmed",
defaultLang: "plaintext",
bypassInlineCode: false,
},
],
],
},
});
export default withMDX(nextConfig);
Code language: JavaScript (javascript)In this config, we have a few things set up to support .mdx files acting as pages, routes, or imports.
We import all the necessary dependencies at the top to make our Next.js app run and support what we need.
Toward the bottom of the file, we add a custom Webpack plugin to run during the server build process only. The plugin is configured using environment variables for the search endpoint and access token:
webpack: (config, { isServer }) => {
if (isServer) {
config.plugins.push(
smartSearchPlugin({
endpoint: env.NEXT_PUBLIC_SEARCH_ENDPOINT,
accessToken: env.NEXT_SEARCH_ACCESS_TOKEN,
})
);
}
return config;
},
Code language: JavaScript (javascript)Create MDX Files And Paths
The next thing we need to do is create our MDX files which will represent our docs pages and routes. In the app folder, create another folder with subfolders that look like this:
app/docs/hello-world
app/docs/example
Then at the last level of the final subfolder, you will add a page.mdx file which is what will be rendered on the browser. So the tree should look like this:

You can name these paths anything you like.
Now, in your page.mdx file is where you can add your MDX content:
export const metadata = {
title: "Test Page",
date: "2023-10-30",
};
# Test Page
This is a test MDX file for verifying the search indexing process.
- Point one
- Point two
Here is some code:
```js
console.log("Hello, world!");
```
## Test Point 2
### Test Point 3
#### Test Point 4
Code language: PHP (php)Most of the content in this file is regular Markdown, but because we are using MDX, you will notice at the top of the file that we have an export syntax to define our metadata directly in the file instead of in the front matter. This allows MDX to be processed as JS, which adds flexibility to using variables or functions in metadata.
In a framework like Next.js, MDX is treated as a module and metadata can be consumed dynamically within React components or by the framework’s data fetching mechanisms.
Feel free to add as many MDX files as you like. I only added two in this article.
Global MDX Components
In order for the @next/mdx package to work and have mdx rendered properly with our configuration in Next.js, it is necessary to have a mdx-components.jsx(or .tsx).
This file will help us customize our component mapping for MDX files, replacing standard HTML tags with React components. In the root of our Next.js app, create a mdx-components.js file and copy and paste this code block in:
import DocsLayout from "@/components/docs-layout";
import Heading from "@/components/heading";
import Link from "next/link";
export function useMDXComponents(components) {
return {
a: (props) => <Link {...props} />,
wrapper: DocsLayout,
h1: (props) => <Heading level={1} {...props} />,
h2: (props) => <Heading level={2} {...props} />,
h3: (props) => <Heading level={3} {...props} />,
h4: (props) => <Heading level={4} {...props} />,
h5: (props) => <Heading level={5} {...props} />,
h6: (props) => <Heading level={6} {...props} />,
...components,
};
}
Code language: JavaScript (javascript)Let’s move on to the search part now.
Smart Search Plugin
To integrate smart search into our Next.js frontend, we need to create a plugin. This plugin will allow us to automate the process of collecting, cleaning, and indexing MDX files from the app/docs directory into our search engine. In the root of the project, create a folder called lib. In this folder, create a file called smart-search-plugin.mjs. In this file, copy and paste this entire code block:
import { hash } from "node:crypto";
import fs from "node:fs/promises";
import path from "node:path";
import { cwd } from "node:process";
import { htmlToText } from "html-to-text";
const queryDocuments = `
query FindIndexedMdxDocs($query: String!) {
find(query: $query) {
documents {
id
}
}
}
`;
const deleteMutation = `
mutation DeleteDocument($id: ID!) {
delete(id: $id) {
code
message
success
}
}
`;
const bulkIndexQuery = `
mutation BulkIndex($input: BulkIndexInput!) {
bulkIndex(input: $input) {
code
documents {
id
}
}
}
`;
let isPluginExecuted = false;
function smartSearchPlugin({ endpoint, accessToken }) {
return {
apply: (compiler) => {
compiler.hooks.done.tapPromise("SmartSearchPlugin", async () => {
if (isPluginExecuted) return;
isPluginExecuted = true;
if (compiler.options.mode !== "production") {
console.log("Skipping indexing in non-production mode.");
return;
}
try {
const pages = await collectPages(path.join(cwd(), "app/docs"));
console.log("Docs Pages collected for indexing:", pages.length);
await deleteOldDocs({ endpoint, accessToken }, pages);
await sendPagesToEndpoint({ endpoint, accessToken }, pages);
} catch (error) {
console.error("Error in smartSearchPlugin:", error);
}
});
},
};
}
async function collectPages(directory) {
const pages = [];
const entries = await fs.readdir(directory, { withFileTypes: true });
for (const entry of entries) {
const entryPath = path.join(directory, entry.name);
if (entry.isDirectory()) {
const subPages = await collectPages(entryPath);
pages.push(...subPages);
} else if (entry.isFile() && entry.name.endsWith(".mdx")) {
const content = await fs.readFile(entryPath, "utf8");
const metadataMatch = content.match(
/export\s+const\s+metadata\s*=\s*(?<metadata>{[\S\s]*?});/
);
if (!metadataMatch?.groups?.metadata) {
console.warn(`No metadata found in ${entryPath}. Skipping.`);
continue;
}
let metadata = {};
try {
// eslint-disable-next-line no-eval
metadata = eval(`(${metadataMatch.groups.metadata})`);
} catch (error) {
console.error("Error parsing metadata:", error);
continue;
}
if (!metadata.title) {
console.warn(`No title found in metadata of ${entryPath}. Skipping.`);
continue;
}
const textContent = htmlToText(content);
const cleanedPath = cleanPath(entryPath);
const id = hash("sha-1", `mdx:${cleanedPath}`);
pages.push({
id,
data: {
title: metadata.title,
content: textContent,
path: cleanedPath,
content_type: "mdx_doc",
},
});
}
}
return pages;
}
function cleanPath(filePath) {
const relativePath = path.relative(cwd(), filePath);
return (
"/" +
relativePath
.replace(/^src\/pages\//, "")
.replace(/^pages\//, "")
.replace(/^app\//, "")
.replace(/\/index\.mdx$/, "")
.replace(/\.mdx$/, "")
// Remove trailing "/page" segment if it appears
.replace(/\/page$/, "")
);
}
async function deleteOldDocs({ endpoint, accessToken }, pages) {
const currentMdxDocuments = new Set(pages.map((page) => page.id));
const variablesForQuery = { query: 'content_type:"mdx_doc"' };
try {
const response = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({
query: queryDocuments,
variables: variablesForQuery,
}),
});
const result = await response.json();
if (result.errors) {
console.error("Error fetching existing documents:", result.errors);
return;
}
const existingIndexedDocuments = new Set(
result.data.find.documents.map((doc) => doc.id)
);
const documentsToDelete = [...existingIndexedDocuments].filter(
(id) => !currentMdxDocuments.has(id)
);
if (documentsToDelete.length === 0) {
console.log("No documents to delete.");
return;
}
for (const docId of documentsToDelete) {
const variablesForDelete = { id: docId };
try {
const deleteResponse = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({
query: deleteMutation,
variables: variablesForDelete,
}),
});
const deleteResult = await deleteResponse.json();
if (deleteResult.errors) {
console.error(`Error deleting document ID ${docId}:`, deleteResult.errors);
} else {
console.log(`Deleted document ID ${docId}:`, deleteResult.data.delete);
}
} catch (error) {
console.error(`Network error deleting document ID ${docId}:`, error);
}
}
} catch (error) {
console.error("Error during deletion process:", error);
}
}
async function sendPagesToEndpoint({ endpoint, accessToken }, pages) {
if (pages.length === 0) {
console.warn("No documents found for indexing.");
return;
}
const documents = pages.map((page) => ({
id: page.id,
data: page.data,
}));
const variables = { input: { documents } };
try {
const response = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({ query: bulkIndexQuery, variables }),
});
if (!response.ok) {
console.error(
`Error during bulk indexing: ${response.status} ${response.statusText}`
);
return;
}
const result = await response.json();
if (result.errors) {
console.error("GraphQL bulk indexing error:", result.errors);
} else {
console.log(`Indexed ${documents.length} documents successfully.`);
}
} catch (error) {
console.error("Error during bulk indexing:", error);
}
}
export default smartSearchPlugin;
Code language: JavaScript (javascript)This is a lot of code so let’s break this down into small chunks.
At the top of the file, we have our imports:
import { hash } from "node:crypto";
import fs from "node:fs/promises";
import path from "node:path";
import { cwd } from "node:process";
import { htmlToText } from "html-to-text";
Code language: JavaScript (javascript)These imports are responsible for the following:
hashThis is Node’s built-incryptomodule. We’ll use this to generate unique identifiers for our documents, ensuring that each piece of content can be tracked as it’s indexed.fs/promisesThis module lets us work with the file system using async/await. We’ll read directories and MDX files and collect their content asynchronously.pathUsed for handling and transforming file pathscwdRetrieves the current working directory of the Node.js processhtml-to-textThis allows us to convert raw HTML (or MDX content that often renders to HTML) into plain text.
Then, We define a GraphQL query to retrieve already indexed documents that match a specific query—in this case, all documents tagged as mdx_doc. This is part of the cleanup process where we compare what’s currently indexed with what we are about to index:
const queryDocuments = `
query FindIndexedMdxDocs($query: String!) {
find(query: $query) {
documents {
id
}
}
}
`;
Code language: PHP (php)Following that, we have a GraphQL mutation for deleting a document by its id. We’ll use this to remove outdated content from the index, ensuring the search results stay accurate:
const deleteMutation = `
mutation DeleteDocument($id: ID!) {
delete(id: $id) {
code
message
success
}
}
`;
Code language: PHP (php)Next, we define a GraphQL mutation for bulk indexing. After collecting all MDX pages, we send them to this mutation in a single request, making the indexing process efficient and seamless.
This line here is a flag that ensures that our indexing logic runs only once per build. Without it, we might accidentally trigger multiple indexing operations, leading to redundant work and inconsistent states.
let isPluginExecuted = false
After that, we have our main plugin function:
function smartSearchPlugin({ endpoint, accessToken }) {
return {
apply: (compiler) => {
compiler.hooks.done.tapPromise("SmartSearchPlugin", async () => {
if (isPluginExecuted) return;
isPluginExecuted = true;
if (compiler.options.mode !== "production") {
console.log("Skipping indexing in non-production mode.");
return;
}
try {
const pages = await collectPages(path.join(cwd(), "app/docs"));
console.log("Docs Pages collected for indexing:", pages.length);
await deleteOldDocs({ endpoint, accessToken }, pages);
await sendPagesToEndpoint({ endpoint, accessToken }, pages);
} catch (error) {
console.error("Error in smartSearchPlugin:", error);
}
});
},
};
}
Code language: JavaScript (javascript)It receives an endpoint from the search API and an access token for authentication. The plugin hooks into the build process via the apply method. We use compiler.hooks.done.tapPromise to run our indexing logic once the build time finishes. This ensures our search index updates after the latest version of the site is compiled.
If we’ve already run this plugin once, we skip running it again. Setting isPluginExecuted to true ensures that even if the build pipeline triggers multiple times, the indexing won’t repeat. Then we make sure we only index in production mode. In dev mode, we don’t want to flood our search index with unstable or temporary content, so we bail out if we are not in production.
We then call collectPages() to gather all MDX documents from app/docs. After this call, pages is an array of all the files we want to index. We log how many we find for transparency.
Then we remove any documents that are no longer relevant by calling deleteOldDocs(). That is followed by adding our current pages to the search index with sendPagesToEndpoint().
If anything goes wrong in our try block, we catch the error, log it out, and do not crash the build. This error handling gives us insight into indexing issues without breaking the build entirely.
The next thing we have is an async function that walks through a given directory, finds all MDX files, extracts their metadata, and preps them for indexing:
async function collectPages(directory) {
const pages = [];
const entries = await fs.readdir(directory, { withFileTypes: true });
for (const entry of entries) {
const entryPath = path.join(directory, entry.name);
if (entry.isDirectory()) {
const subPages = await collectPages(entryPath);
pages.push(...subPages);
} else if (entry.isFile() && entry.name.endsWith(".mdx")) {
const content = await fs.readFile(entryPath, "utf8");
const metadataMatch = content.match(
/export\s+const\s+metadata\s*=\s*(?<metadata>{[\S\s]*?});/
);
if (!metadataMatch?.groups?.metadata) {
console.warn(`No metadata found in ${entryPath}. Skipping.`);
continue;
}
Code language: JavaScript (javascript)If we don’t find any metadata in the file, we log a warning and skip this file. Our indexing workflow requires metadata – specifically a title – to proper,y index the content.
Here, we parse the metadata using eval:
let metadata = {};
try {
metadata = eval(`(${metadataMatch.groups.metadata})`);
} catch (error) {
console.error("Error parsing metadata:", error);
continue;
}
if (!metadata.title) {
console.warn(`No title found in metadata of ${entryPath}. Skipping.`);
continue;
}
Code language: JavaScript (javascript)If the metadata is invalid or can’t be evaluated, we log an error and skip the file. Then we ensure that the metadata includes a title. If it’s not a valid document for indexing, we skip it.
Next, we convert the MDX content to plain text for indexing. This gives our search engine clean text without HTML tags. Then we run cleanPath() to transform the file’s absolute path into a user-facing URL path. It ensures that the app/docs/my-page/page.mdx becomes a neat URL, like /docs/my-page. After that, a unique ID for this document is generated based on the cleaned path. Using a hash ensures that the same path always yields the same ID, which is needed for identifying when documents change or need deletion:
const textContent = htmlToText(content);
const cleanedPath = cleanPath(entryPath);
const id = hash("sha-1", `mdx:${cleanedPath}`);
Code language: JavaScript (javascript)The next lines add a new document to the pages array. It includes the ID, metadata, raw text, and other helpful attributes that the search API needs:
pages.push({
id,
data: {
title: metadata.title,
content: textContent,
path: cleanedPath,
content_type: "mdx_doc",
},
});
}
}
return pages;
}
Code language: JavaScript (javascript)The following function cleanPath takes a file’s absolute path, converts it to a project-relative path, and then strips out unwanted prefixes. It also removes trailing extensions and ensures any trailing /page segments are gone.
function cleanPath(filePath) {
const relativePath = path.relative(cwd(), filePath);
return (
"/" +
relativePath
.replace(/^src\/pages\//, "")
.replace(/^pages\//, "")
.replace(/^app\//, "")
.replace(/\/index\.mdx$/, "")
.replace(/\.mdx$/, "")
// Remove trailing "/page" segment if it appears
.replace(/\/page$/, "")
);
}
Code language: JavaScript (javascript)In this following async function, we take a snapshot of all the current document IDs we are about to index. We then prepare a GraphQL query to find all existing mdx_doc documents that might no longer be relevant.
async function deleteOldDocs({ endpoint, accessToken }, pages) {
const currentMdxDocuments = new Set(pages.map((page) => page.id));
const variablesForQuery = { query: 'content_type:"mdx_doc"' };
Code language: JavaScript (javascript)Following that, we perform a network request to the search GraphQL endpoint to fetch a list of already indexed documents. After sending the request, we await response.json() for the server’s reply. We get the data returned in JSON format which we parse into a JS object.
Then we check for errors and if something is wrong, we log it.
try {
const response = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({
query: queryDocuments,
variables: variablesForQuery,
}),
});
const result = await response.json();
if (result.errors) {
console.error("Error fetching existing documents:", result.errors);
return;
}
Code language: JavaScript (javascript)Here, we take the documents returned from our earlier GraphQL query (result.data.find.documents) and map them down to their IDs. We then wrap these IDs in a JavaScript Set. A Set gives us fast lookups, helping us easily check whether a given document ID is present.
const existingIndexedDocuments = new Set(
result.data.find.documents.map((doc) => doc.id)
);
Code language: JavaScript (javascript)Then we identify documents to delete here. This filters out any id that is not in the current MDX documents and all IDs that are currently indexed but should not be anymore:
const documentsToDelete = [...existingIndexedDocuments].filter(
(id) => !currentMdxDocuments.has(id)
);
Code language: JavaScript (javascript)If documentsToDelete is empty, it means our search index is perfectly aligned with our current documents—nothing to remove. In that case, we log a message and return early.
if (documentsToDelete.length === 0) {
console.log("No documents to delete.");
return;
}
Code language: JavaScript (javascript)Now we iterate over each document ID in documentsToDelete. For each, we create a variablesForDelete object that will be passed into a GraphQL mutation. This mutation will delete the document with that specific id from the search index.
for (const docId of documentsToDelete) {
const variablesForDelete = { id: docId };
Code language: JavaScript (javascript)The next lines send a GraphQL mutation request to the search endpoint to remove a specific document from the index. It posts a deleteMutation query along with the necessary variables (including the document ID to delete). After the network call completes, it processes the JSON response to confirm whether the deletion was successful.
try {
const deleteResponse = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({
query: deleteMutation,
variables: variablesForDelete,
}),
});
const deleteResult = await deleteResponse.json();
Code language: JavaScript (javascript)This section checks whether the deletion request was successful or not. If the GraphQL response includes any errors, it logs those errors along with the document ID that failed to delete. Otherwise, it confirms that the document was successfully removed by logging a success message. Should any network issues occur during the process, those are also caught and logged. After processing all documents set for deletion, if a broader error occurs, it’s logged to help diagnose issues in the overall deletion process:
if (deleteResult.errors) {
console.error(
`Error deleting document ID ${docId}:`,
deleteResult.errors
);
} else {
console.log(
`Deleted document ID ${docId}:`,
deleteResult.data.delete
);
}
} catch (error) {
console.error(`Network error deleting document ID ${docId}:`, error);
}
}
} catch (error) {
console.error("Error during deletion process:", error);
}
}
Code language: JavaScript (javascript)Following that, we set up the data needed to index newly collected pages. If there are no pages to index, it simply logs a warning and exits. Otherwise, it transforms the array of page objects into a format required by the GraphQL bulkIndex mutation, packaging each page’s ID and associated metadata into a documents array. It then wraps that array into a variables object, preparing the payload that will be sent to the search endpoint.
async function sendPagesToEndpoint({ endpoint, accessToken }, pages) {
if (pages.length === 0) {
console.warn("No documents found for indexing.");
return;
}
const documents = pages.map((page) => ({
id: page.id,
data: page.data,
}));
const variables = { input: { documents } };
Code language: JavaScript (javascript)A the end of this code block, we send the prepared list of documents to the search service using a POST request. It includes the bulkIndexQuery and the variables containing all documents that need indexing. If the server responds with a non-OK status, it logs an error and stops. Once a successful response comes in, it checks for any GraphQL-level errors and logs them. If there are no errors, it confirms that the documents have been successfully indexed. If a network or unexpected error occurs at any point, it’s caught and reported, ensuring any issues are visible and can be addressed.
try {
const response = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({ query: bulkIndexQuery, variables }),
});
if (!response.ok) {
console.error(
`Error during bulk indexing: ${response.status} ${response.statusText}`
);
return;
}
const result = await response.json();
if (result.errors) {
console.error("GraphQL bulk indexing error:", result.errors);
} else {
console.log(`Indexed ${documents.length} documents successfully.`);
}
} catch (error) {
console.error("Error during bulk indexing:", error);
}
}
export default smartSearchPlugin;
Code language: JavaScript (javascript)Components Directory
The next thing we have to do is go over the components needed in this project. The components directory will be at the root of our Next.js 15 project.
The search-bar.jsx file
The search bar in our project is a client-side search component with a keyboard-accessible modal. Since it is a large block of code, let’s break down the code line by line.
At the start of the file, we declare this as a client-side component with “use client.” This tells Next.js to run this component on the client allowing the use of hooks like useState and useEffect.
All our necessary imports for this component follow that.
Next, we define and export our SearchBar component, which is our main component. It renders the search bar and handles all the logic.
Then we have the state and variable references:
export default function SearchBar() {
const [items, setItems] = useState([]);
const [inputValue, setInputValue] = useState("");
const [isModalOpen, setIsModalOpen] = useState(false);
const dialogReference = useRef(null);
const router = useRouter();
Code language: JavaScript (javascript)Here is what the state and variable references do:
const [items, setItems] = useState([]);
This initializes items state as an empty array. It stores the search results fetched from the API.
const [inputValue, setInputValue] = useState("");
This initializes the input value state as an empty string and tracks the current value of the search input field.
const [isModalOpen, setIsModalOpen] = useState(false);
This sets up the isModalOpen state as false and controls the visibility of the search modal.
const dialogReference = useRef(null);
This creates a reference to dialogReference which is set to null. It references the modal dialog DOM element to detect clicks outside the modal.
const router = useRouter();
This sets the Next.js router instance. It allows navigation to different routes programmatically.
After the state and references, we have our modal control functions:
const openModal = useCallback(() => {
setIsModalOpen(true);
setInputValue("");
setItems([]);
}, []);
const closeModal = useCallback(() => setIsModalOpen(false), []);
Code language: JavaScript (javascript)This defines the openModal function calling useCallback. It opens the search modal and resets the input and items. The dependency array is empty so the function is memoized once and doesn’t change across renders.
Then we define the closeModal function using useCallback. This closes the search modal by setting isModalOpen to false. The array is empty here to ensure consistent reference.
The next block of code is event handlers:
const handleOutsideClick = useCallback(
(event) => {
const isClickOutsideOfModal = event.target === dialogReference.current;
if (isClickOutsideOfModal) {
closeModal();
setInputValue("");
setItems([]);
}
},
[closeModal]
);
const handleKeyDown = useCallback(
(event) => {
if (event.metaKey && event.key === "k") {
event.preventDefault();
openModal();
}
if (event.key === "Escape") {
closeModal();
}
},
[openModal, closeModal]
);
Code language: JavaScript (javascript)The first event handler closes the modal when the user clicks outside of it.
The next event handles keyboard shortcuts on a Mac. If command k is pressed, it prevents default behavior and opens the modal. If the escape key is pressed, it closes it.
The following is an event listener:
useEffect(() => {
document.addEventListener("keydown", handleKeyDown);
return () => document.removeEventListener("keydown", handleKeyDown);
}, [handleKeyDown]);
Code language: JavaScript (javascript)This attaches the key-down event listener to the document when the component mounts and cleans up when it unmounts.
Next, we have our debounced fetch function:
const debouncedFetchItems = useRef(
debounce(async (value) => {
if (!value) {
setItems([]);
return;
}
try {
const response = await fetch(
`/api/search?query=${encodeURIComponent(value)}`
);
if (!response.ok) {
console.error(
`Search API error: ${response.status} ${response.statusText}`
);
setItems([]);
return;
}
const data = await response.json();
if (Array.isArray(data)) {
setItems(data);
} else {
console.error("Search API returned unexpected data:", data);
setItems([]);
}
} catch (error) {
console.error("Error fetching search results:", error);
setItems([]);
}
}, 500)
).current;
Code language: JavaScript (javascript)This creates a debounced function that fetches search results, limiting API calls to one every 500 milliseconds. useRef stores the debounced function so it is not recreated on every render. debounce wraps the async function to delay execution.
In the body of the function, we have fetched search results from the API based on the user’s input value. It checks if the value is empty or falsy, it will clear items and it exits.
The API call fetches data from api/search, encoding the value to handle special characters. If the response is not OK, it logs an error and clears items. The response JSON is parsed and then checks if data is an array. If it is, it updates the items. Otherwise, it logs an error and clears.
The error handling then catches any network or parsing errors, logs them and clears items.
Following that we have our cleanup effect:
useEffect(() => {
return () => {
debouncedFetchItems.cancel();
};
}, [debouncedFetchItems]);
Code language: JavaScript (javascript)This useEffect cleanup hook cancels any pending debounced function calls when the component unmounts. The next block of code is our downshift combobox configuration:
const {
isOpen,
getMenuProps,
getInputProps,
getItemProps,
highlightedIndex,
openMenu,
closeMenu,
} = useCombobox({
items,
inputValue,
defaultHighlightedIndex: 0,
onInputValueChange: ({ inputValue: newValue }) => {
setInputValue(newValue);
debouncedFetchItems(newValue);
if (newValue.trim() === "") {
closeMenu();
} else {
openMenu();
}
},
onSelectedItemChange: ({ selectedItem }) => {
if (selectedItem) {
closeModal();
router.push(selectedItem.path);
}
},
itemToString: (item) => (item ? item.title : ""),
});
Code language: JavaScript (javascript)This configures the combobox behavior using the useCombobox hook from Downshift.
At the start of the const, we have our destructured values:
isOpen: Boolean indicating if the menu is open.getMenuProps: Props to spread onto the menu (<ul>) element.getInputProps: Props to spread onto the input element.getItemProps: Props to spread onto each item (<li>) element.highlightedIndex: The index of the currently highlighted item.openMenu: Function to open the menu.closeMenu: Function to close the menu.
After that, we have our config options:
items: The array of items to display (search results).inputValue: The current value of the input field.defaultHighlightedIndex: Sets the default highlighted item (index 0).onInputValueChange: Called when the input value changes.onSelectedItemChange: Called when an item is selected.itemToString: Converts an item to a string representation for display.
Then, the onInputValueChange handler updates state and manages menu visibility when the input value changes. If the menu is empty, it closes. Otherwise, it is left open.
The onSelectedItemChange handler handles actions when an item is selected from the search results. If a selected item exists, it closes the modal and navigates to the selected item’s path with router.push.
The last thing in this code block is the itemToString function. This converts an item to a string for display purposes. If there is an item, it will return its title and if not, it returns an empty string.
Lastly, we have our JSX return statement:
return (
<>
{/* Search Button */}
<button
className="inline-flex items-center rounded-md bg-gray-800 px-2 py-1.5 text-sm font-medium text-gray-400 hover:bg-gray-700"
onClick={openModal}
type="button"
>
<span className="hidden md:inline">
<span className="pl-3">Search docs or posts...</span>
<kbd className="ml-8 rounded bg-gray-700 px-2 py-1 text-gray-400">
⌘K
</kbd>
</span>
</button>
{/* Modal */}
{isModalOpen && (
<div
className="bg-black fixed inset-0 z-50 flex items-start justify-center bg-opacity-50 backdrop-blur-sm"
onClick={handleOutsideClick}
onKeyDown={(event) => {
if (event.key === "Enter" || event.key === " ") {
handleOutsideClick(event);
}
}}
role="button"
tabIndex="0"
ref={dialogReference}
>
{/* Modal Content */}
<div
className="relative mt-10 w-full max-w-4xl rounded-lg bg-gray-800 p-6 shadow-lg"
role="dialog"
tabIndex="-1"
>
{/* Combobox */}
<div
role="combobox"
aria-expanded={isOpen}
aria-haspopup="listbox"
aria-controls="search-results"
>
{/* Input Field */}
<div className="relative">
<input
autoFocus
{...getInputProps({
placeholder: "What are you searching for?",
"aria-label": "Search input",
className:
"w-full pr-10 p-2 bg-gray-700 text-white placeholder-gray-400 border border-gray-700 rounded focus:outline-none focus:ring-2 focus:ring-blue-500",
})}
/>
{/* Close Button */}
<button
type="button"
className="absolute right-2 top-1/2 -translate-y-1/2 transform text-xs text-gray-400 hover:text-white"
onClick={closeModal}
>
Esc
</button>
</div>
{/* Results List */}
<ul
{...getMenuProps({
id: "search-results",
})}
className="mt-2 max-h-60 overflow-y-auto"
>
{isOpen &&
items &&
items.length > 0 &&
items.map((item, index) => (
<li
key={item.id}
{...getItemProps({
item,
index,
onClick: () => {
closeModal();
router.push(item.path);
},
onKeyDown: (event) => {
if (event.key === "Enter") {
closeModal();
router.push(item.path);
}
},
})}
role="option"
aria-selected={highlightedIndex === index}
tabIndex={0}
className={`flex w-full cursor-pointer items-center justify-between px-4 py-4 ${
highlightedIndex === index
? "bg-blue-600 text-white"
: "bg-gray-800 text-white"
}`}
>
<span className="text-left">{item.title}</span>
<span className="text-right text-sm text-gray-400">
{item.type === "mdx_doc" ? "Doc" : "Blog"}
</span>
</li>
))}
</ul>
{/* No Results Message */}
{isOpen && items.length === 0 && (
<div className="mt-2 text-gray-500">No results found.</div>
)}
</div>
</div>
</div>
)}
</>
);
Code language: JavaScript (javascript)This JSX return statement renders a dynamic and interactive search feature. It starts with a button styled to initiate the search modal and displays a keyboard shortcut (⌘K) for convenience. When clicked, the button opens a full-screen modal overlay with a slight blur effect, visually focusing the user on the search functionality while the rest of the page dims.
The modal includes a responsive, styled search input field that is immediately focused and supports live autocomplete through the useCombobox hook. Below the input field, a scrollable list dynamically displays search results, with highlighted and selectable options that navigate the user to their respective pages when clicked or when the Enter key is pressed. If no results are found, a subtle message is shown.
Additionally, the modal is fully accessible, with ARIA roles and attributes for the combobox and options, and it can be closed by clicking outside, pressing the Escape key, or using the close button within the modal. In this example code, we’re using Tailwind CSS, but you can use whatever styling solution works best for your project.
Layout, Heading, and NavBar
There are 3 more components that we will go over in our components folder.
The docs-layout component is a wrapper that applies consistent styling to docs pages. This ensures proper spacing and a clean readable layout for its child content.
The heading component creates custom-styled headings with clickable anchor links, making it easy for users to share or navigate to specific sections. It dynamically adjusts styles based on the heading level.
Lastly, the Navbar component provides a global navigation bar with a link to the home page on the left and a SearchBar component on the right for usability.
There is not much to the code in these components. You can reference them in the repo here:
https://github.com/Fran-A-Dev/smart-search-with-app-router/blob/main/components/nav-bar.jsx
https://github.com/Fran-A-Dev/smart-search-with-app-router/blob/main/components/heading.jsx
https://github.com/Fran-A-Dev/smart-search-with-app-router/blob/main/components/docs-layout.jsx
The route.js File
In Next.js 15 App Router, we need to set up a route handler that allows us to create a custom request handler for our search API route. This API route handles GET requests for search functionality by querying a GraphQL endpoint for documents matching a user-provided query string.
In the app folder, create a subfolder called api. In that subfolder, create another subfolder called search. Within that search folder, create a file called route.js. Copy and paste this code block:
import { NextResponse } from "next/server";
import { ReasonPhrases, StatusCodes } from "http-status-codes";
function cleanPath(filePath) {
return (
filePath
.replace(/^\/?src\/pages/, "")
.replace(/^\/?pages/, "")
.replace(/\/index\.mdx$/, "")
.replace(/\.mdx$/, "") || "/"
);
}
export async function GET(request) {
const endpoint = process.env.NEXT_PUBLIC_SEARCH_ENDPOINT;
const accessToken = process.env.NEXT_SEARCH_ACCESS_TOKEN;
const { searchParams } = new URL(request.url);
const query = searchParams.get("query");
if (!query) {
return NextResponse.json(
{ error: "Search query is required." },
{ status: StatusCodes.BAD_REQUEST }
);
}
const graphqlQuery = `
query FindDocuments($query: String!) {
find(query: $query) {
total
documents {
id
data
}
}
}
`;
try {
const response = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({
query: graphqlQuery,
variables: { query },
}),
});
if (!response.ok) {
return NextResponse.json(
{ error: ReasonPhrases.SERVICE_UNAVAILABLE },
{ status: StatusCodes.SERVICE_UNAVAILABLE }
);
}
const result = await response.json();
if (result.errors) {
return NextResponse.json(
{ errors: result.errors },
{ status: StatusCodes.INTERNAL_SERVER_ERROR }
);
}
const seenIds = new Set();
const formattedResults = [];
for (const content of result.data.find.documents) {
const contentType =
content.data.content_type || content.data.post_type || "mdx_doc";
let item = null;
if (contentType === "mdx_doc" && content.data.title) {
const path = content.data.path ? cleanPath(content.data.path) : "/";
item = {
id: content.id,
title: content.data.title,
path,
type: "mdx_doc",
};
} else if (
(contentType === "wp_post" || contentType === "post") &&
content.data.post_title &&
content.data.post_name
) {
item = {
id: content.id,
title: content.data.post_title,
path: `/blog/${content.data.post_name}`,
type: "post",
};
}
if (item && !seenIds.has(item.id)) {
seenIds.add(item.id);
formattedResults.push(item);
}
}
return NextResponse.json(formattedResults, { status: StatusCodes.OK });
} catch (error) {
console.error("Error fetching search data:", error);
return NextResponse.json(
{ error: ReasonPhrases.INTERNAL_SERVER_ERROR },
{ status: StatusCodes.INTERNAL_SERVER_ERROR }
);
}
}
Code language: JavaScript (javascript)First, we import NextResponse from Next.js, to return responses in App Router-based endpoints. We also bring in ReasonPhrases and StatusCodes from http-status-codes to ensure our responses are consistent and human-readable, making it easier to understand which HTTP statuses we’re returning and why.
The cleanPath function then takes an internal file path—like one found in a Next.js src/pages or app directory—and transforms it into a clean, user-friendly URL. It strips away any directory prefixes (/src/pages, /pages), and removes filename extensions or index placeholders (such as index.mdx).
If all content is removed, it defaults to /, ensuring every piece of content resolves to a neat, presentable URL.
In the next few lines, we handle incoming search requests. The GET function is the main entry point for the endpoint. It begins by reading environment variables NEXT_PUBLIC_SEARCH_ENDPOINT and NEXT_SEARCH_ACCESS_TOKEN—these determine where we’ll send our search queries and how we authenticate with the search service.
Next, it extracts the query parameter from the request’s URL. If no query is provided, the function quickly returns a 400 Bad Request response, ensuring that the caller knows a query string is mandatory.
Then we have a GraphQL query that finds all documents matching the user’s query string:
export async function GET(request) {
const endpoint = process.env.NEXT_PUBLIC_SEARCH_ENDPOINT;
const accessToken = process.env.NEXT_SEARCH_ACCESS_TOKEN;
const { searchParams } = new URL(request.url);
const query = searchParams.get("query");
if (!query) {
return NextResponse.json(
{ error: "Search query is required." },
{ status: StatusCodes.BAD_REQUEST }
);
}
const graphqlQuery = `
query FindDocuments($query: String!) {
find(query: $query) {
total
documents {
id
data
}
}
}
`;
Code language: JavaScript (javascript)In the next few lines, we send a POST request to the search endpoint, including the GraphQL query and the search term. This request includes authentication via a bearer token to ensure only authorized calls go through.
If the response indicates an issue—like the server being unreachable—it immediately returns a 503 Service Unavailable message to let the caller know the search service isn’t currently accessible.
After verifying the response is good, it converts the response to JSON. If the server replies with GraphQL errors, the code returns a 500 Internal Server Error response, signaling that something went wrong on the server side.
try {
const response = await fetch(endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${accessToken}`,
},
body: JSON.stringify({
query: graphqlQuery,
variables: { query },
}),
});
if (!response.ok) {
return NextResponse.json(
{ error: ReasonPhrases.SERVICE_UNAVAILABLE },
{ status: StatusCodes.SERVICE_UNAVAILABLE }
);
}
const result = await response.json();
if (result.errors) {
return NextResponse.json(
{ errors: result.errors },
{ status: StatusCodes.INTERNAL_SERVER_ERROR }
);
}
Code language: JavaScript (javascript)Following that, the documents are returned by the search service, turning them into a more usable, standardized format. It uses a Set called seenIds to keep track of which document IDs have already been processed, ensuring that no duplicates end up in the final results.
For each content object, the code identifies the document’s type—whether it’s an mdx_doc or a WordPress post—so that it knows how to handle its title and path.
For mdx_doc types, it cleans the path using cleanPath() to create a user-friendly URL. For WordPress posts, it constructs a blog URL based on the post’s name. This ensures that each document is transformed into a consistent, meaningful shape: it has an id, a title, and a path that can be used directly in the frontend.
Finally, each document is only added to the results if it hasn’t been seen before. Once processed, formattedResults ends up with a clean, non-redundant list of items.
const seenIds = new Set();
const formattedResults = [];
for (const content of result.data.find.documents) {
const contentType =
content.data.content_type || content.data.post_type || "mdx_doc";
let item = null;
if (contentType === "mdx_doc" && content.data.title) {
const path = content.data.path ? cleanPath(content.data.path) : "/";
item = {
id: content.id,
title: content.data.title,
path,
type: "mdx_doc",
};
} else if (
(contentType === "wp_post" || contentType === "post") &&
content.data.post_title &&
content.data.post_name
) {
item = {
id: content.id,
title: content.data.post_title,
path: `/blog/${content.data.post_name}`,
type: "post",
};
}
if (item && !seenIds.has(item.id)) {
seenIds.add(item.id);
formattedResults.push(item);
}
}
Code language: JavaScript (javascript)Lastly, the code returns a 200 OK response containing the formattedResults array if all is good. This gives the user a clear set of neatly formatted search results.
If an exception occurs, the catch block logs the issue for diagnostic purposes and responds with a 500 Internal Server Error. This ensures that the client knows there is an error and logs a record of the error to troubleshoot.
Test the Search Functionality
That is all the code we need to make this work. Stoked!!!
Now, let’s test in production mode.
Run this command in your terminal to create a production build in your Next.js project:
npm run build
When you run a build, you will notice this output in your terminal:

You should be even more stoked because the output shows the plugin working with the indexing process being output!
Now, start the server to test the application in production:
npm run start
On the page, click on the search bar and type whatever title or associated content you have with a WordPress blog post in your WP backend. You should see this:
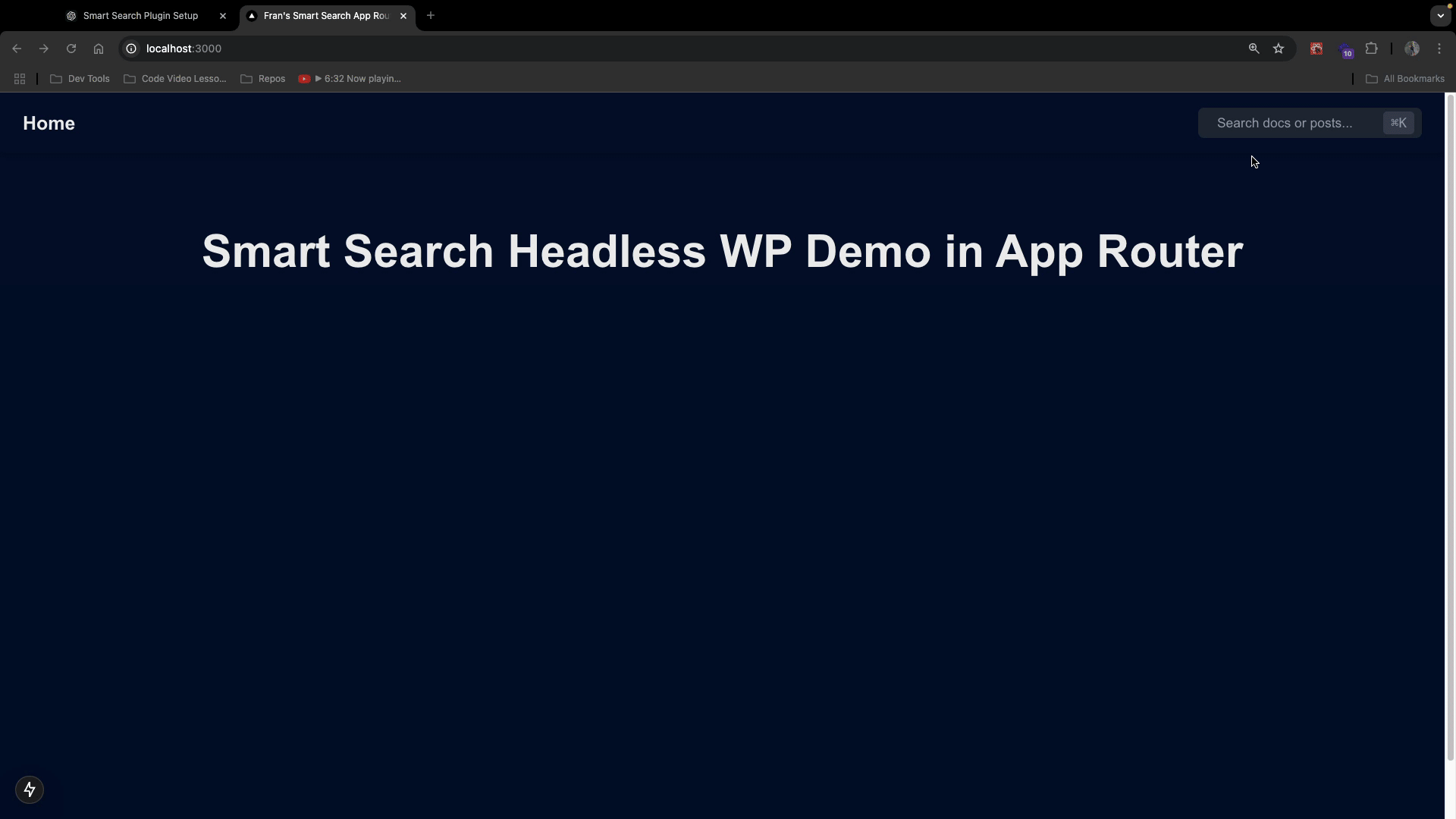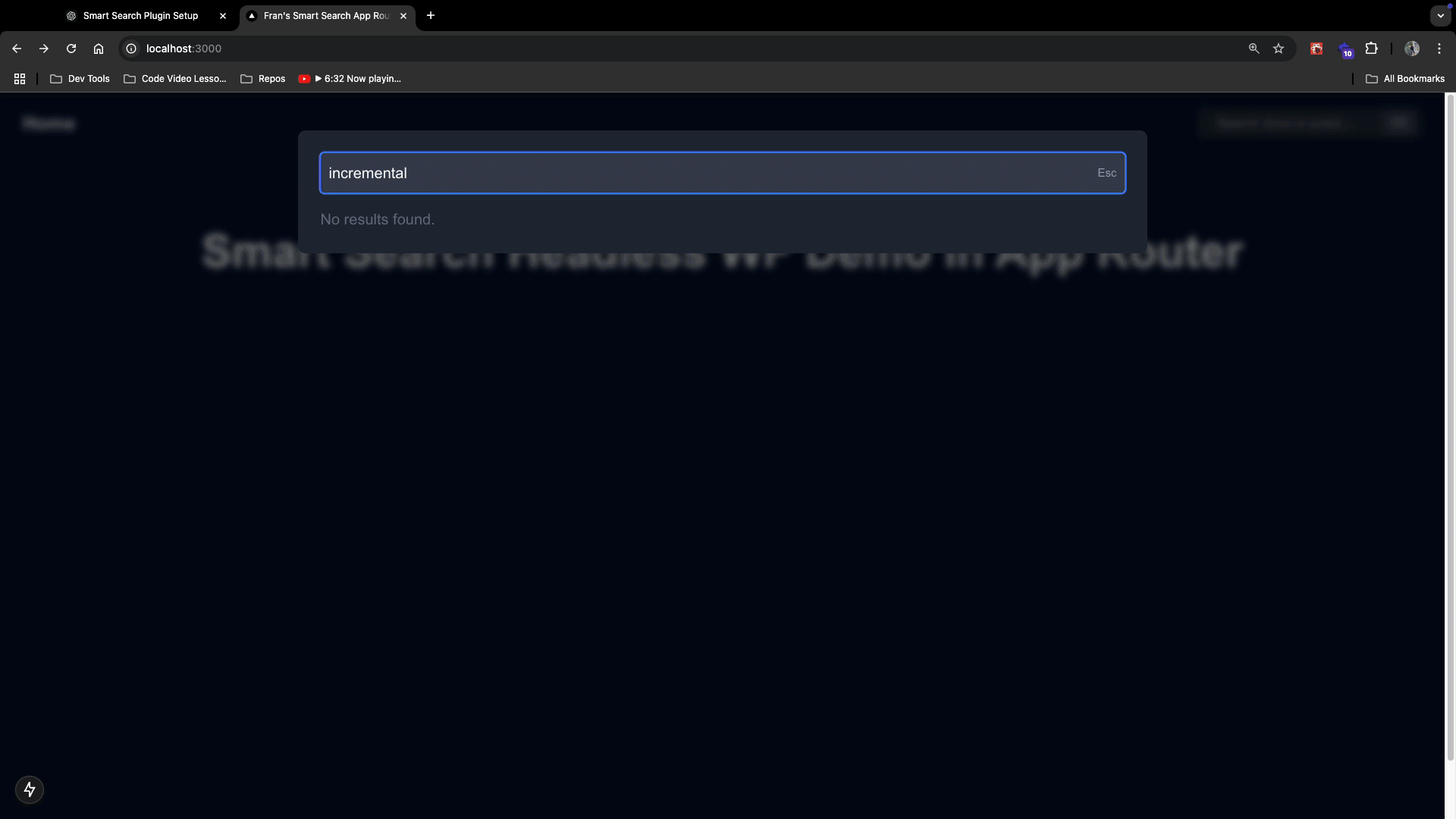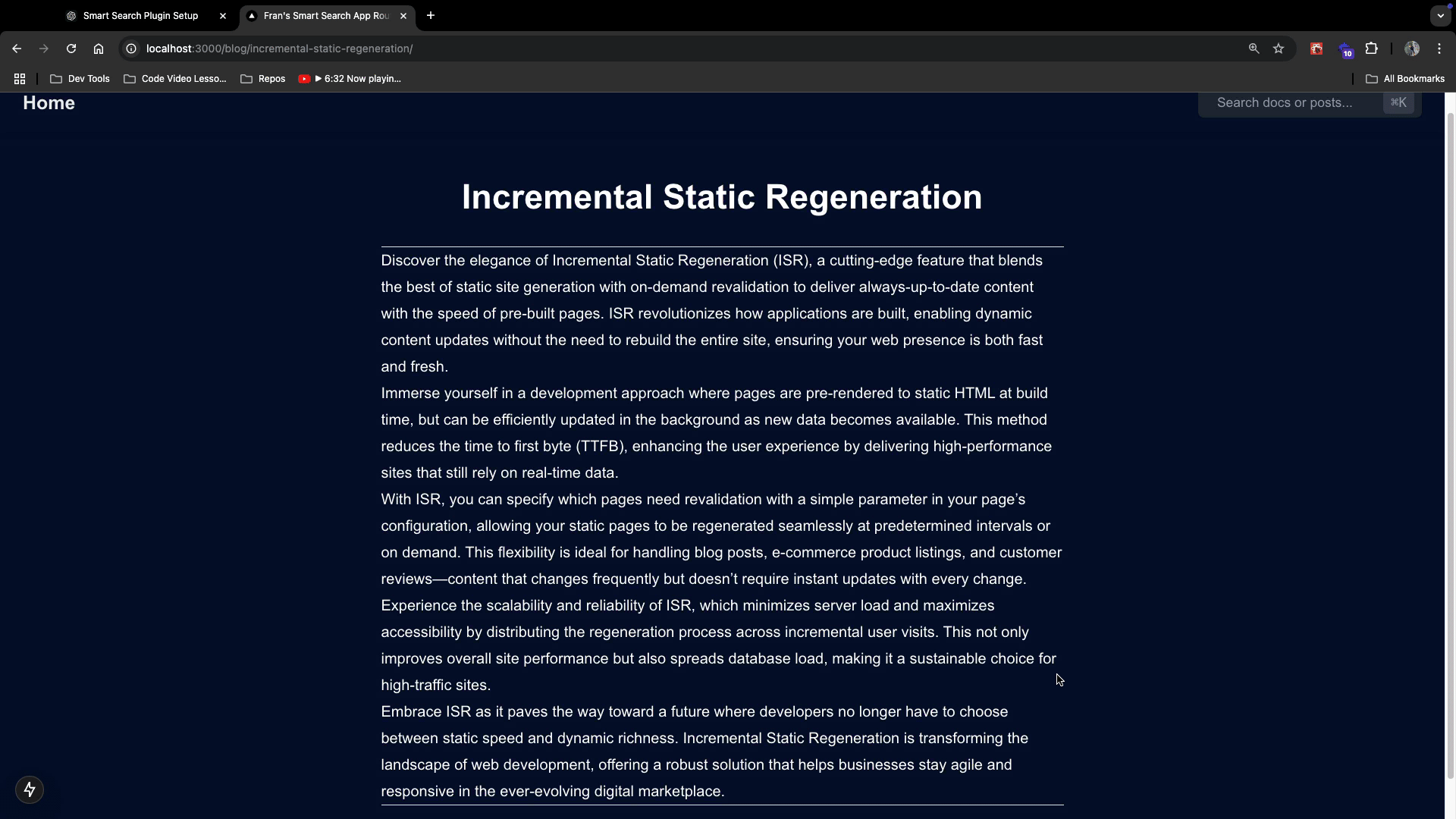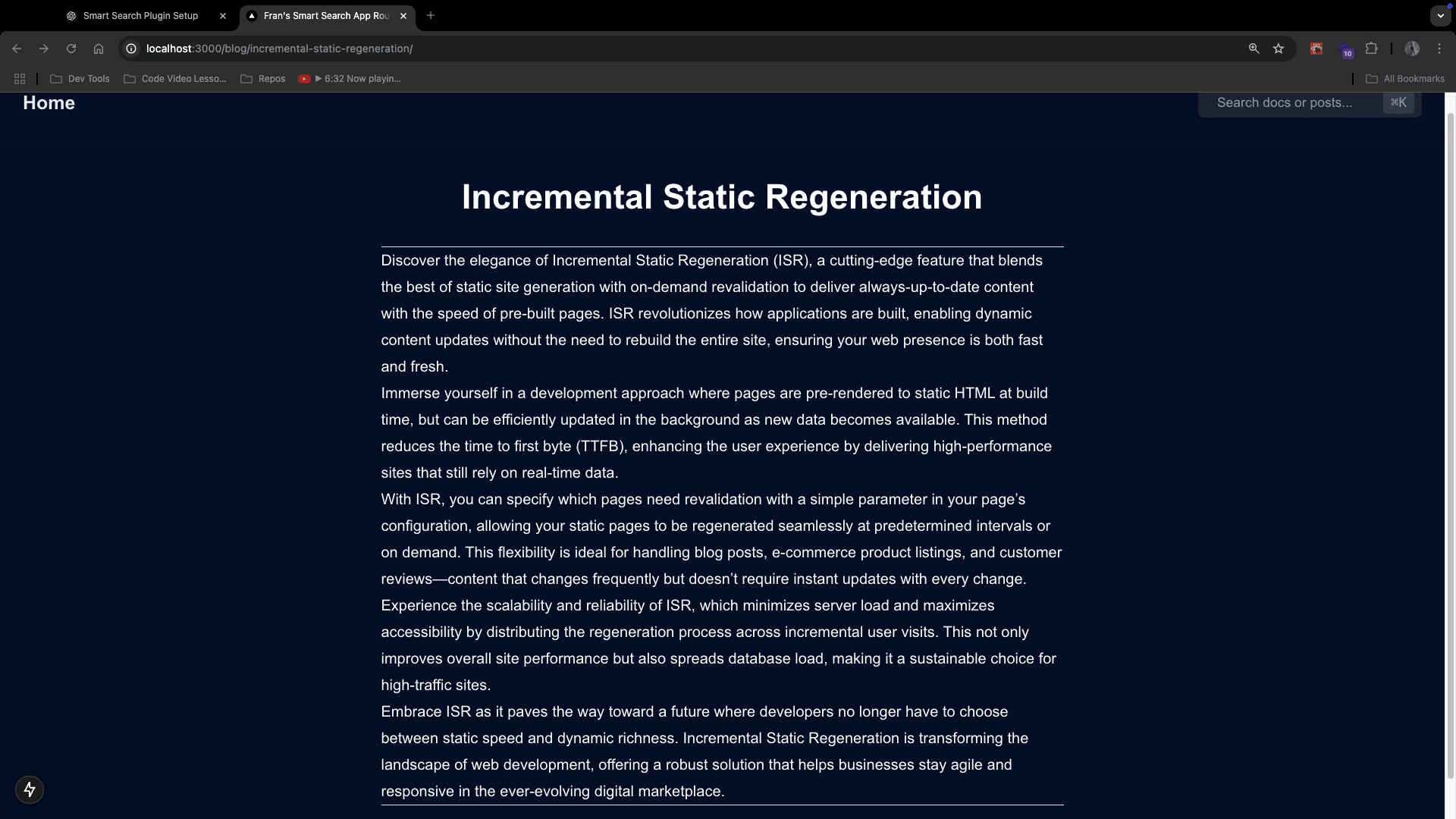
Then, try typing a title or content associated with your MDX docs and you should see this:
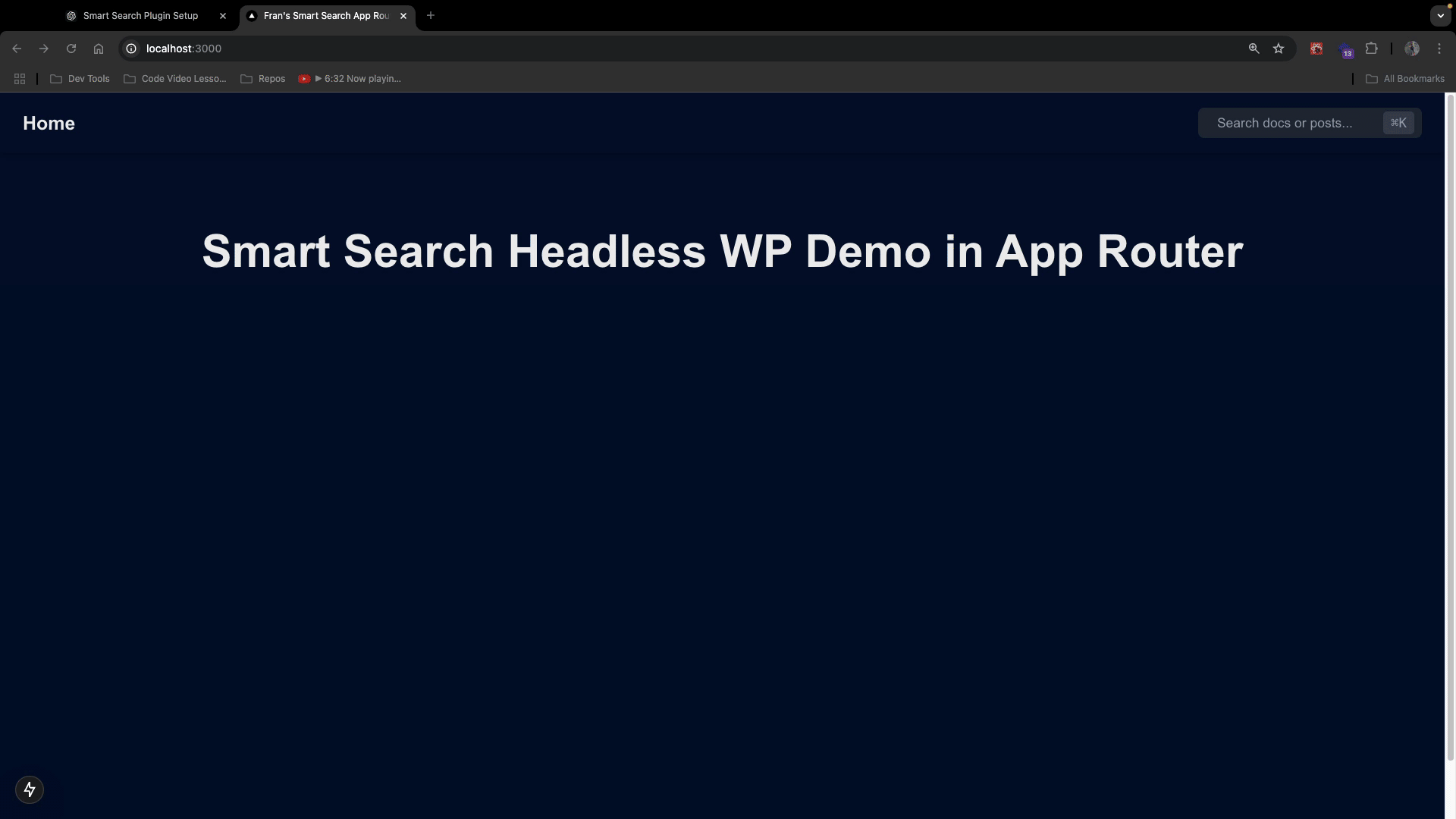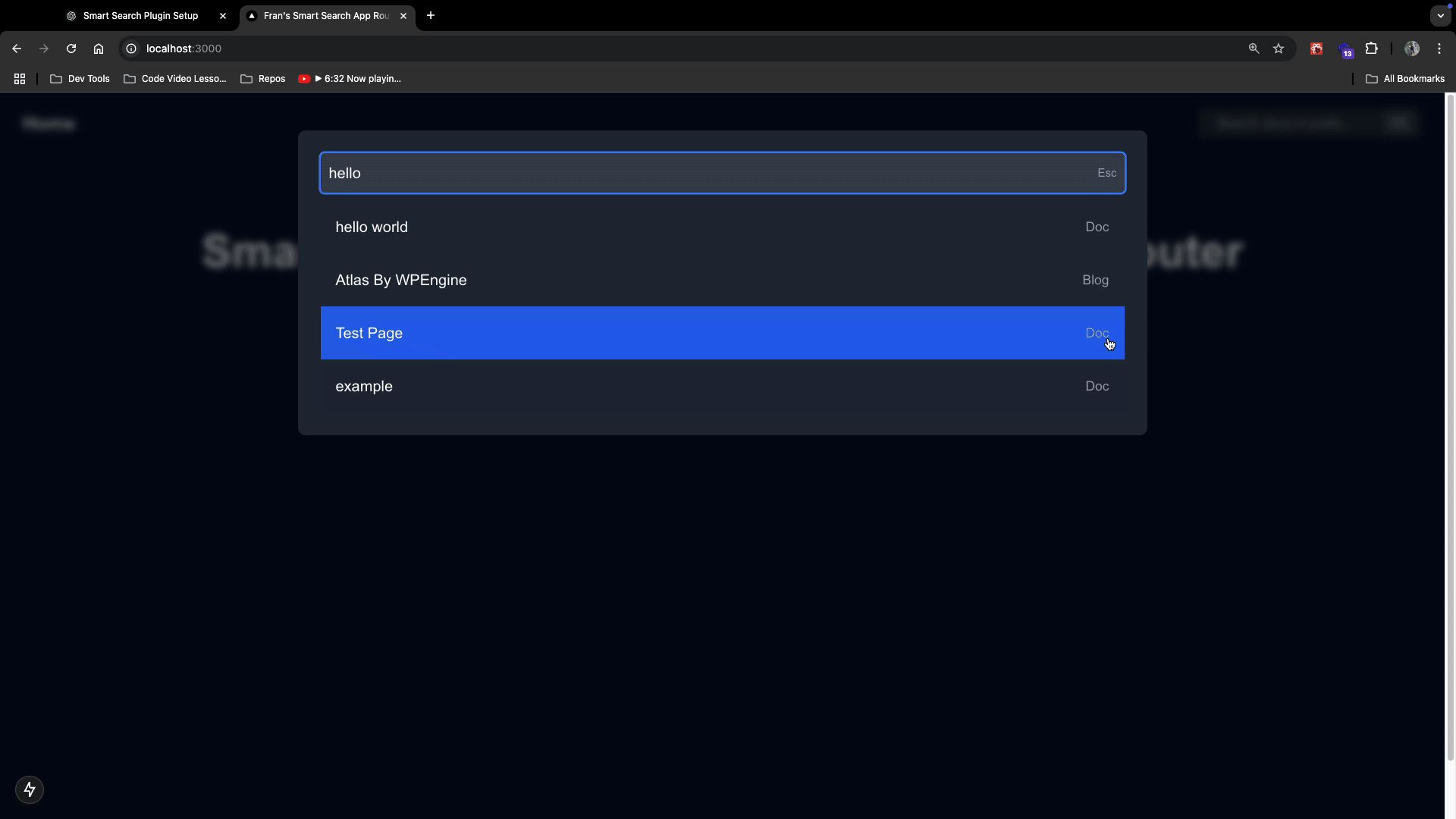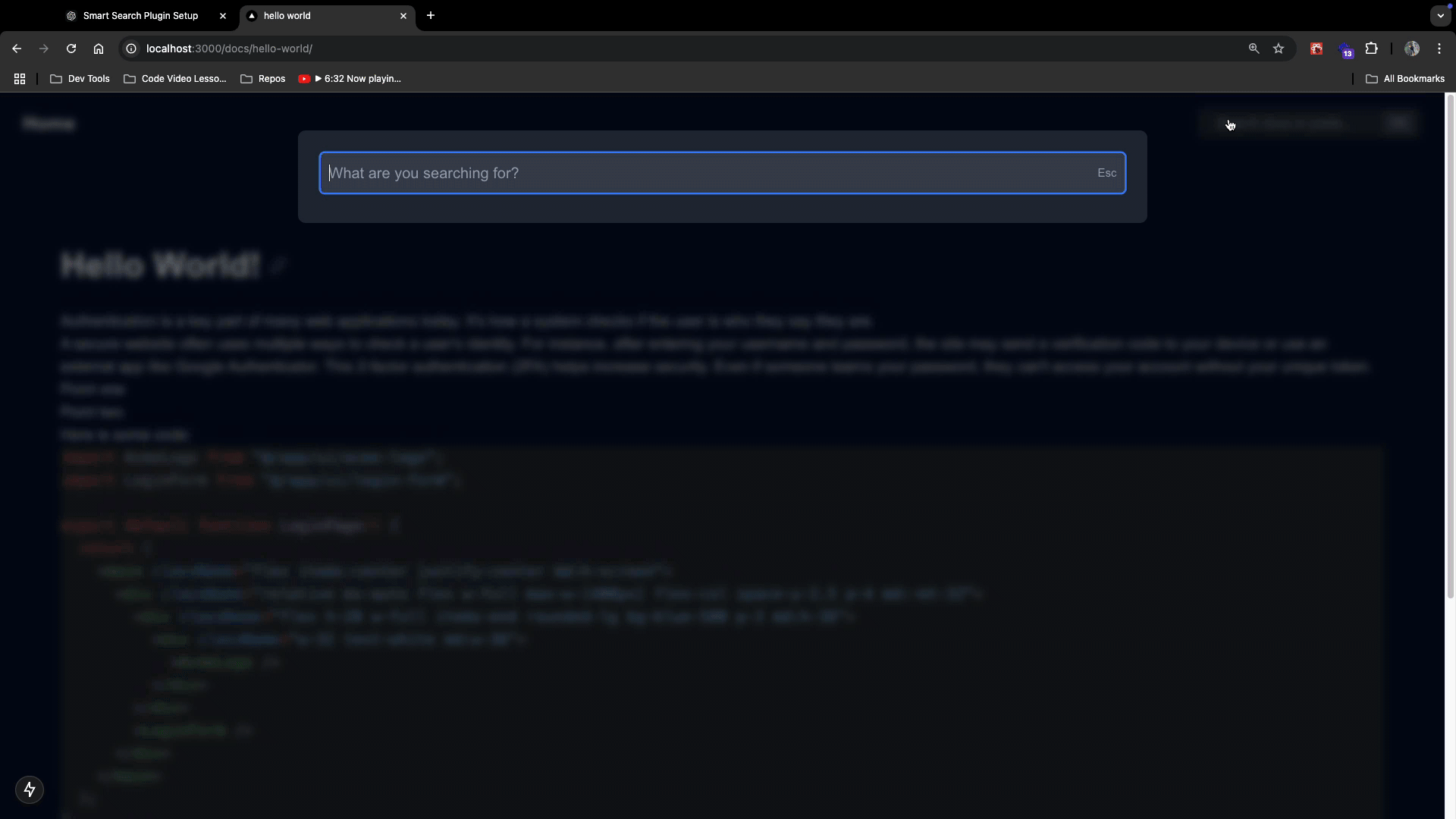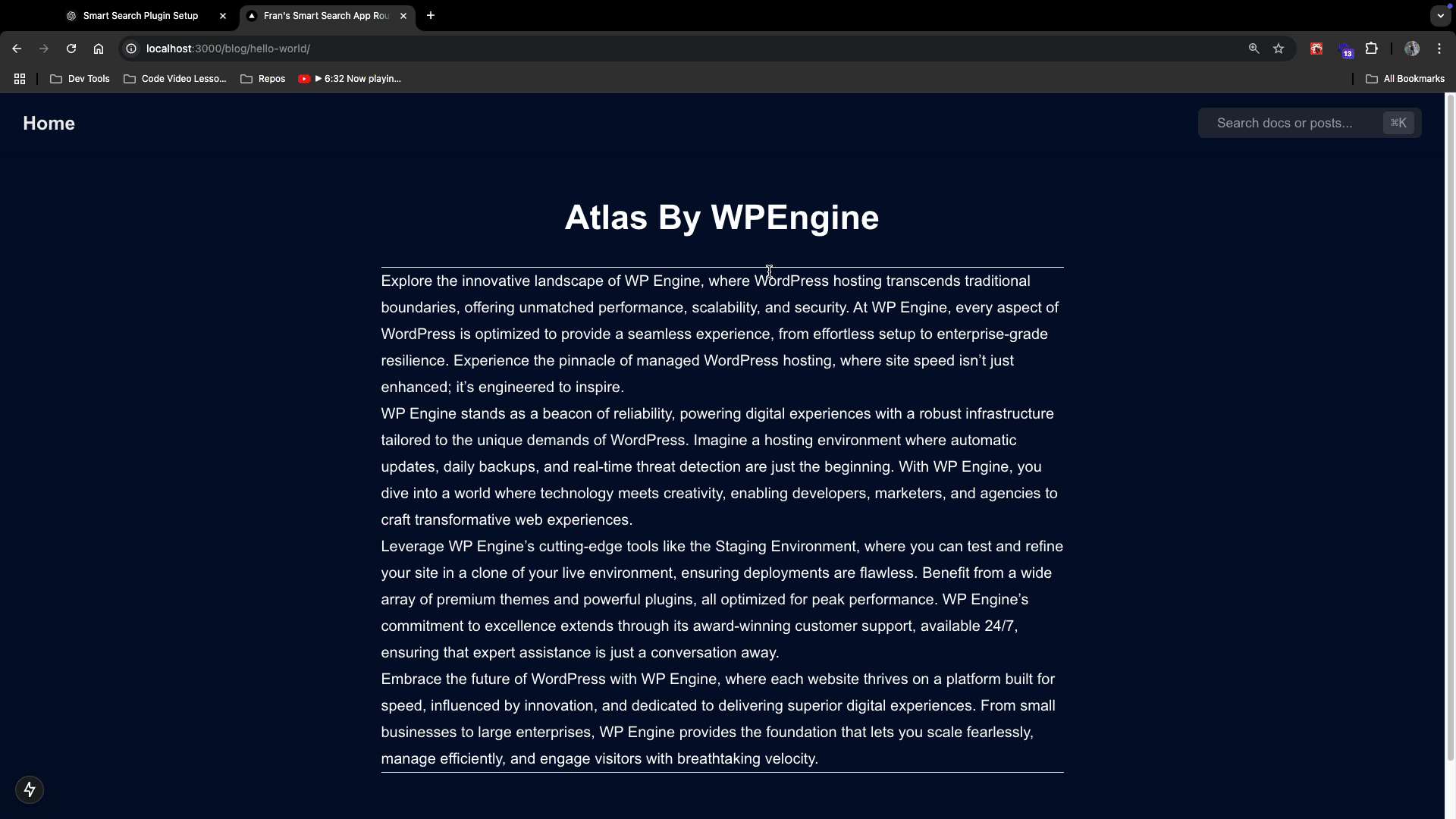
Notice that the search results will return both documents and blog posts if they contain similar data! When you click that search result, it will take you to the correct path of the MDX page or the WordPress blog post. (Remember, the WP posts are coming from the dynamic route file you already have setup )
The good thing is, that we have labeled them accordingly so our users know which one they are.
Conclusion
The WP Engine Smart Search plugin is an enhanced search solution for regular WordPress and headless WordPress. We hope this tutorial helps you better understand how to set it up and use it in a headless app.
As always, we’re super stoked to hear your feedback and learn about the headless projects you’re working on, so hit us up in our Discord!